
Using machine learning to predict (& prevent!) injuries in endurance athletes: Part 2
Alan Couzens, M.Sc. (Sports Science)
Dec 19th, 2016

In my last post I looked at a different, but very important, side of performance modeling – modeling the risk of injury in athletes. I suggested that this is a key missing part in the performance puzzle. After all, a massive chronic training load doesn’t do you much good if you get injured before expressing it on race day! No, in addition to tracking that load-performance relationship, those who are serious about performance should probably have a good handle on their load-injury relationship as well!
In that post, I began to outline a method for doing just that – using some machine learning techniques to help your computer work out that relationship for you based on previous training-injury data that you feed it. I went into some of the specifics of how you want to prepare that data for your computer to make sense of it. In this post we’re going to go that step further and actually use our computer to build a predictive model so that you can assess your own risk of injury based on training load and lifestyle state at any point in time and, more importantly, use that information to change your approach when needed to head off injuries before they occur.
So let's get to it...
If you’re following along from the first post, you should have something that looks like the following saved in a file called injury.py…
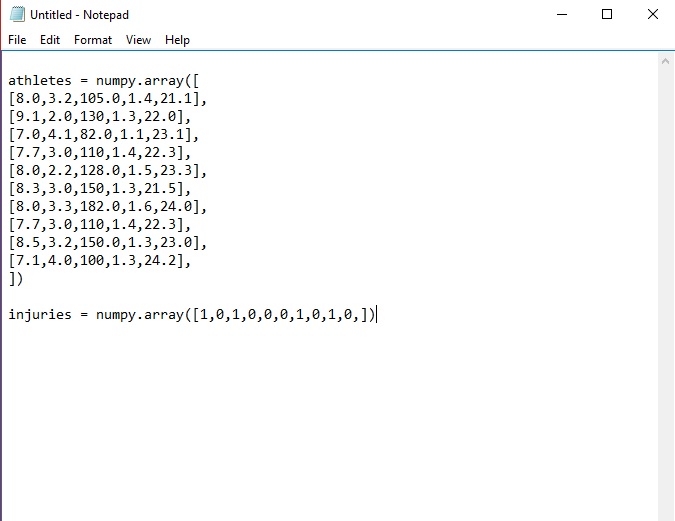
As a recap, these 2 arrays contain data from several training blocks representing 5 inputs in the 'athletes' array
- Sleep (in hours),
- Stress (rating out of 5)
- Training load (TSS/day),
- Acute:Chronic load ratio
- Body Mass Index
...along with a separate output array ('injuries') that tells us whether each of the above combos led to an injured (1) or an uninjured (0) athlete
You might be surprised to learn that, with the above data, you’ve already written the bulk of the ‘code’ for your injury predictor model! That’s the power of the Python language! See, some very smart folks have already written all the tricky math code for us and all we need to do to build our model is to ‘plug & play’ by importing some of those modules.
This is, literally, as simple as writing ‘import ‘… whatever code we want to bring in.
For machine learning tasks, there is a whole library of useful code available on scikit-learn (http://scikit-learn.org/stable/) If you already have Python on your machine (if you’re working with a mac, you probably do. If not, you can get it here https://www.python.org/downloads/), you can install this library of code in its entirety with a simple command:
from your command line.
Once you’ve got that library, building models for an individual athlete is super simple!
Let’s return to our injury predictor model saved in Notepad to show just how simple…
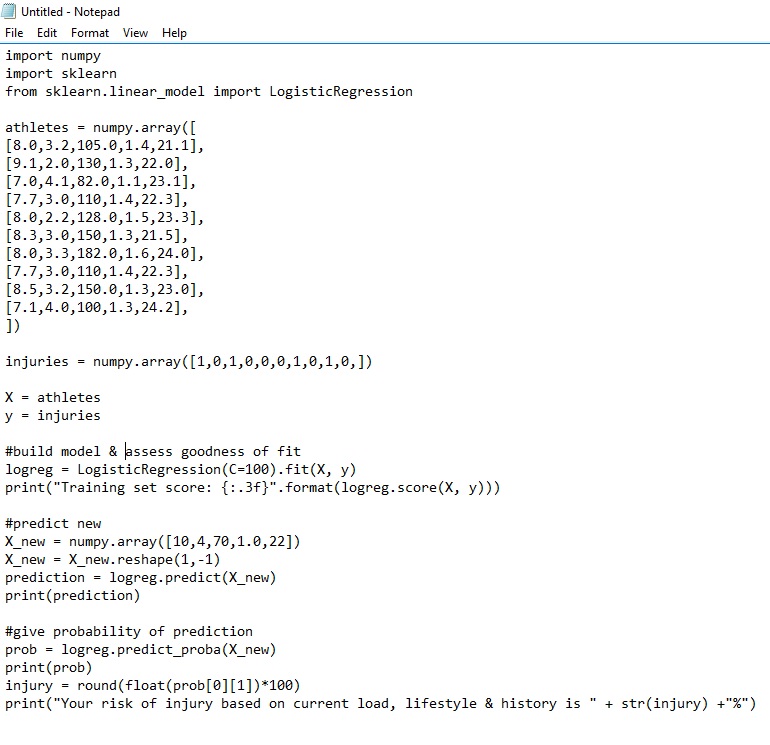
With the addition of only 15 lines of code we have a working model that predicts the likelihood of injury for a given athlete! Let’s work through it real quick and then we’ll get to the fun bit of applying it to assess your own likelihood of injury based on current training load & lifestyle factors…
On the first 3 lines we import all of the math code that we need for our calculations including the logistic regression function from the scikit-learn library.
The next 15 or so lines should be familiar. They represent the training data that we fed the model in last week’s blog, with the first block being an array that holds values for sleep, stress, training load, ATL/CTL ratio and BMI) for a number of training blocks. The second array contains the information on whether the above led to injury (score of 1) or non-injury (score of 0) for each of those blocks. This is the part of the code that you would replace with your own data to make the model individual to you. As I said last week, this data is the crux of an effective model. More data for a given athlete = better individual model.
Then, (in one line of code!) we build our predictive model and assess how accurate it is with respect to the data. The key line that builds our model is...
logreg = LogisticRegression(C=100).fit(X,y)
This tells scikit to build a logistic regression model with the X and y data given above.
The next line tells it to give us a 'score' that assesses how closely the model fits the data. This is akin to the R^2 value that you might be familiar with if you’ve ever played with scatterplots and linear regression in Excel.
Then we get to the fun stuff of using this model to predict the likelihood of injury given some new data. Here we feed it an array for a new training block of [10,4,70,1.0,22] where the athlete will sleep 10hrs a night, have an average (life) stress score of 4 out of 5, have a training load of 70TSS/d, an ATL/CTL ratio of 1.0 and a BMI of 22.
We then ask the model to go to work and predict whether these inputs will lead to an injured athlete. Beyond just asking it to make the call of injured v not-injured, in the next section of code, we ask our model to give us an actual probability number for the % likelihood that the above inputs will lead to an injury. This can help us make the call of how much risk is too much for each athlete in each circumstance. Finally we ask it to print this % to the console.
Running this program is as simple as going to the command line, navigating to where the file lives (in this case in a folder called ‘python_work’ on my desktop) and then typing “python injury.py” This runs the script. This will spit out the results as follows…
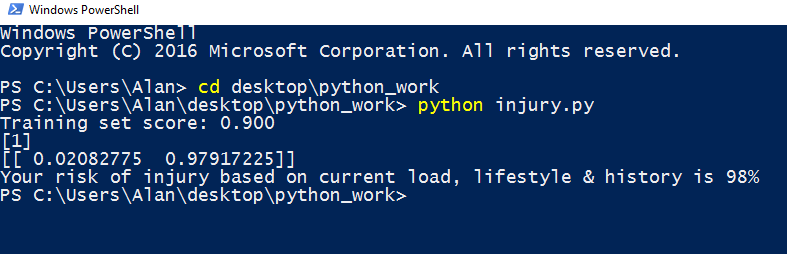
With these inputs for this athlete, the model predicts a 98% likelihood of injury if we proceed with that plan. No bueno!
Building a working predictive model is as simple as that!
Yes, for the ML aficionados, there are a number of things that we would want to do to improve our model – splitting our data set into a training/test set & tweaking the C parameter to ensure we don’t overfit the model to the current data etc but the above provides a good starting point to outline we go about building predictive models in an athletic/coaching context.
But... prediction is only the first step in coming up with something that’s of practical 'real world' use to the coach or athlete! Once we know that an athlete is likely to get injured based on current inputs, how can we step in to prevent that? Isn't that the goal - a 'Minority Report' scenario, where we head off negative outcomes before they occur? Yes, in more ways than I care to admit, you can think of me as the endurance sports version of a 'Precog' :-)

In the above scenario that we ran, it looks like this athlete is in a pretty stressful period of their life (mean ranking of 4 out of 5!) So, what if we cut the training load back during this stressful period to only 35TSS/d (only 50% of their long term 'chronic' load)? To see how this change would affect the athlete's injury risk we go back into our script and change the new array to [10, 4, 35, 0.5, 22] , i.e. change the 3rd and 4th input variables related to load.Then we run the script again with the new inputs….
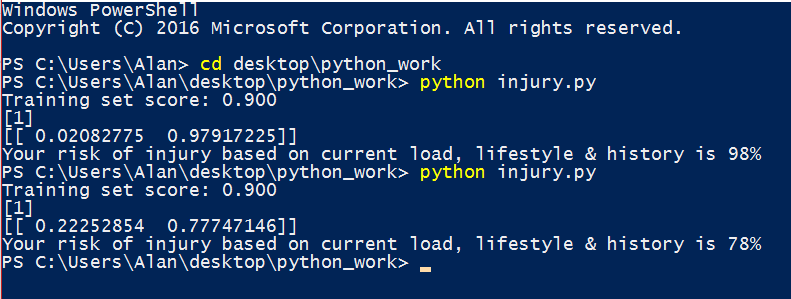
...78%. We reduced the risk of injury by 20% by bringing the load down for this high life stress block. Ah, that’s a bit better.
We can use this method to play around with the inputs until we come up with something that falls within an acceptable level of risk. Of course, doing this by hand is tedious and with a bit more code, we can create an algorithm that does this for us, i.e we plug in our acceptable risk level, and lifestyle variables and the computer spits out the training load to put us there. I’ll look at some of these ‘optimization algorithms’ in a future post.
But, in my next post I want to finish up the series on injury prediction by applying an even more powerful & descriptive algorithm (the Decision Tree) to look at some of the patterns that I’ve observed running these injury predictor analyses on my own athletes. Chances are that it will take you a while to build your own data up & looking at a more general model from a big group of athletes with a whole lot of data can provide a good starting point.
Until then...
Train smart,
AC
TweetDon't miss a post! Sign up for my mailing list to get notified of all new content....